

更新2025/12/01
这次我们发布了Spin版的底模,在一定程度上对模型的收敛会更加快,并且对哑音的优化会有一定的效果。
说明,由于Spin版团队打包时,只上传了底模文件,所以替换文件48k.json以及rmvpe.pt在Contentvec版本中,请优先下载Contentvec版的底膜。
前言
本底模完全跳过RVC_v2默认底模从头开始训练的一款预训练模型,默认RVC_v2的模型说话人是109位,使用50小时英文数据集进行训练。而Mygf-f048k基于contentvec嵌入模型,使用中英日三种语言数据集进行预训练,语言数据集大约在100小时左右,配合预训练rmvpe高音指导。
替换
值得注意的是,本款模型由于增加说话人,您需要替换原本的RVC_v2的底膜配置文件。
configs\v2\48k.json
下载的是官方开源项目并且版本为V1006,那么它一定会在这个位置,在此之前,您可以备份该文件在替换。
其次,还需要替换掉rmvpe模型。
assets\rmvpe\rmvpe.pt
训练模型一定要替换这两个文件,否则会导致训练失败或训练的模型沙哑。
参数
本次底膜的参数比RVC_v2两倍之多,预训练的参数如下:
- 说话人:308位
- 语言:中/美/日
- 语料:>100/小时
- step:≈1.2M
- 训练周期:24 day
详细教程
文件打包的目录如下
- rmvpe.pt
- 48k.json
- D_Mygf-f048K.pth
- G_Mygf-f048K.pth
将1和2文件按照第二部中的替换解压到指定的位置上,3和4您可以放在任何一个可访问目录下,至此新底膜部署完毕。
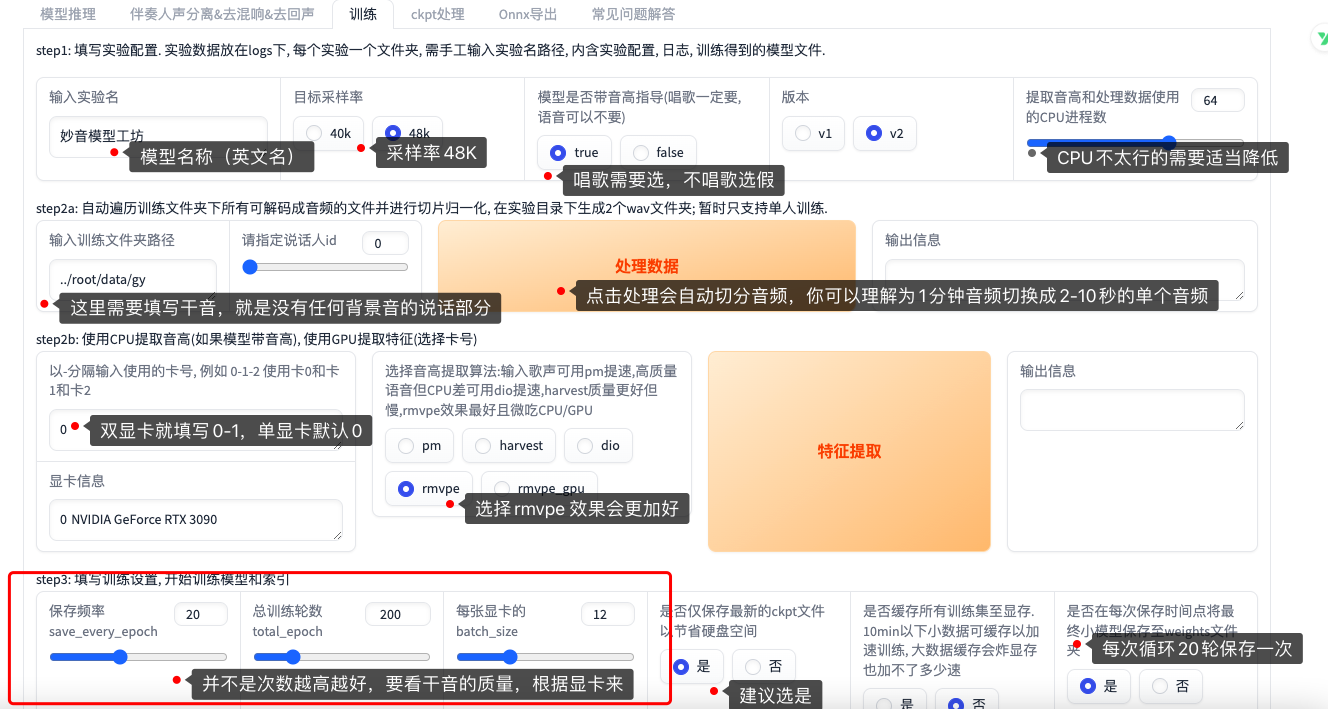
在训练中请先选择[目标采样率->48K]之后在修改[加载预训练底模G路径]以及[加载预训练底模D路径]的路径。
![图片[1]-Mygf-f048k使用文档 - 妙音-RVC音色模型工坊-妙音-RVC音色模型工坊](https://klrvc.com/wp-content/uploads/2025/09/05f13ed21020250929105454-1024x349.png)
(修改底膜路径)
在训练期间,控制台输出:
DEBUG:infer.lib.infer_pack.models:gin_channels: 256, self.spk_embed_dim: 308
则代表底膜正确识别加载成功。这个时候,所有步骤都已经完成。
可能出现的问题
报错[109,xxxx]
请回到替换这一步,正确的替换48K.json文件
高音沙哑
请替换rmvpe.pt模型,正确加载新指导模型。
优点
- 不会出现口胡。
- 支持不同语料互相转换(日转中会出现“大佐”音,使用Mygf-f048k)训练的模型,则不会出现。
- 6分钟左右的语料也能完美训练。
- 音色更加接近。
使用新底膜训练的模型
https://klrvc.com/mxgf/3488.html
https://klrvc.com/mxgf/3471.html
https://klrvc.com/mxgf/3451.html
https://klrvc.com/mxgf/3432.html
https://klrvc.com/mxgf/3415.html
以上就是新底模的全部部署教程,按照教程一步一步操作即可。
最后附上底膜损失图
![图片[2]-Mygf-f048k使用文档 - 妙音-RVC音色模型工坊-妙音-RVC音色模型工坊](https://klrvc.com/wp-content/uploads/2025/09/cd06ec509e20250929110911.png)
以上测试均在2.2.231006版本中进行:https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/releases/tag/2.2.231006

















请登录后查看评论内容