

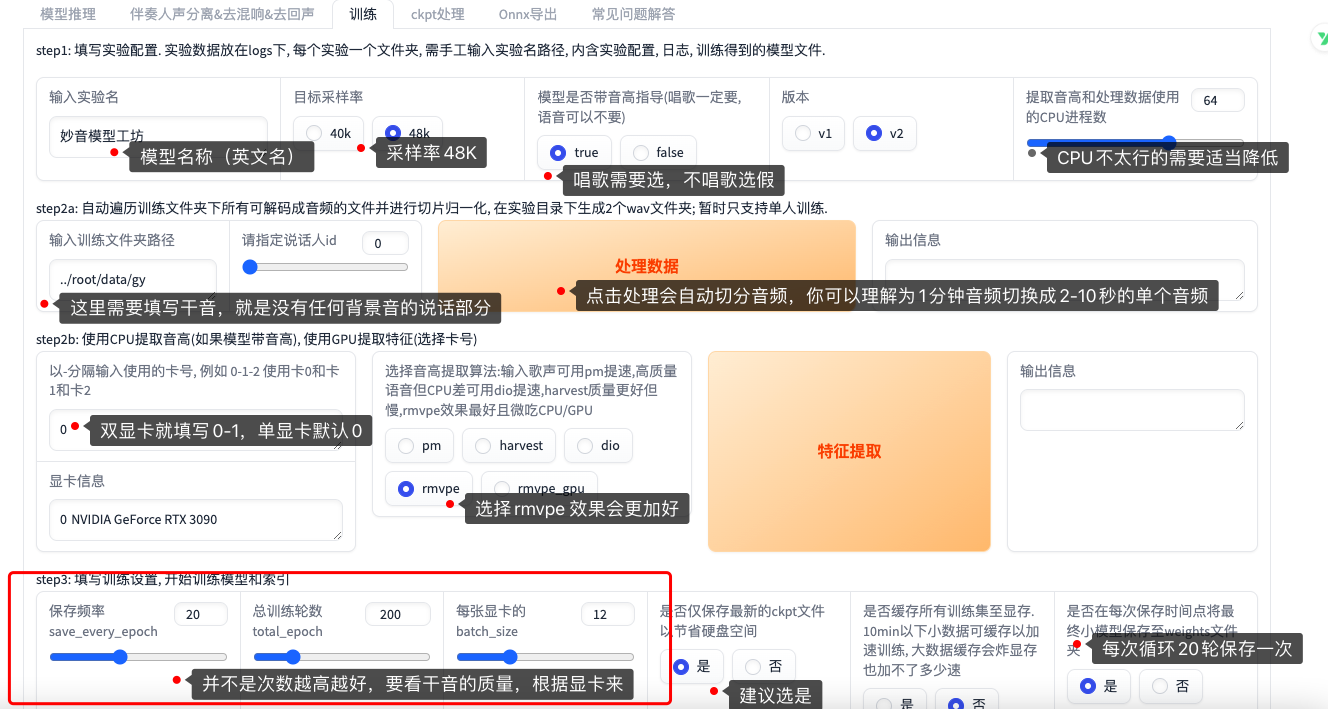
这波模型放给大家,是一个少御音,利用SPIN重新构建的一个48k底模训练而成。
SPIN基于自监督学习框架,通过创新的说话人扰动和噪声不变性训练策略,能够更有效地解耦语音内容与说话人特征。其核心优势体现在:
1.训练效率:相比ContentVec,SPIN收敛速度更快,所需计算资源更少。
2.表征质量:在说话人相似度和语音自然度方面表现更优。
3.噪声鲁棒性:对背景噪声具有更好的抵抗能力。
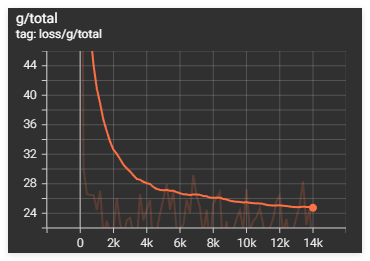
目前放出来的是还没有完全跑完的预训练模型训练的模型,在测试中,我们使用相同的一段数据进行测试模型ContentVec对比SPIN,它的确会在某些地方改变哑音以及高音,由于没有完全跑完,我们不确定它最后的效果如何。
推理模型你不需要改变任何原始rvc来进行。
(This model, which we’re releasing now, features a reduced level of speech control and is trained using a 48k base model reconstructed using SPIN.
SPIN is based on a self-supervised learning framework and employs innovative speaker perturbation and noise invariance training strategies to more effectively decouple speech content from speaker features. Its core advantages are:
1. Training efficiency: Compared to ContentVec, SPIN converges faster and requires fewer computational resources.
2. Representation quality: It performs better in terms of speaker similarity and speech naturalness.
3. Noise robustness: It has better resistance to background noise.
The model currently being released is a pre-trained version that hasn’t been fully run. In testing, we compared the ContentVec model with SPIN using the same dataset. It does indeed alter muffled and high-pitched sounds in some places. Since it hasn’t been fully run, we’re unsure of its final performance.
For the inference model, you don’t need to modify any of the original RVC.)

















请登录后查看评论内容