

![[炼丹师必看]如何看懂损失(LOSS)函数曲线图](https://klrvc.com/wp-content/uploads/2025/03/7ad52299fb20250305121601-1024x638.jpeg)

前沿
近期包小柏用AI“复刻”了女儿,其中在声音这块使用了当下最流行的Ai软件RVC来复刻还原声音,此外还有视频网站音乐区up主掀了“AI孙燕姿”的风潮,都是使用了这一块的Ai软件来制作还原音色。
动手试一试
这里我们使用
对比其他的云端,Autodl显卡种类多,相对于价格会比较便宜很多,或者如果不想训练的话可以直接用其他已经制作好的高质量模型,这里推荐妙音工坊,千款免费的大模型,也算是制作的比较全的一款模型网站妙音-RVC声音克隆工坊。
在选择算力显卡的时候默认推荐选择3080Ti,价格和算力都是比较实惠的。
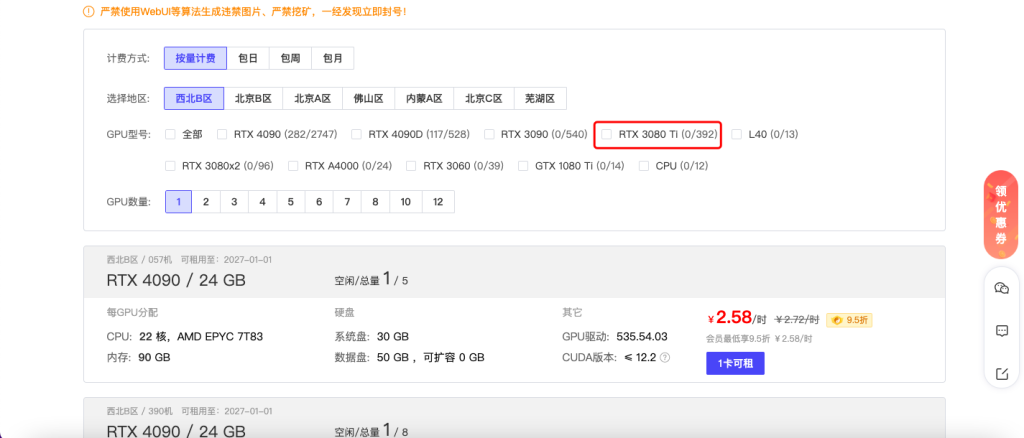
选择社区镜像RVC-第一个
这里需要注意的是V4推荐40以上的显卡,V3适合30以上的显卡,其他V1和V2版本不推荐使用。
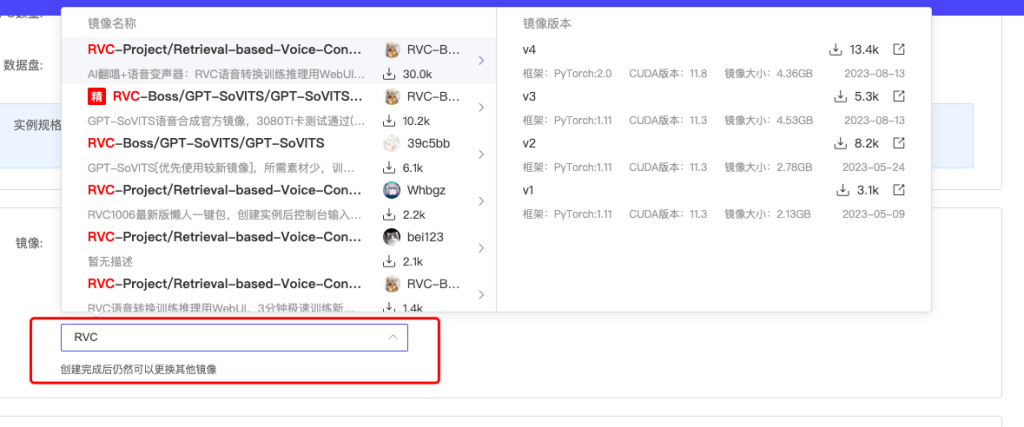
创建完成后我们进入控制台点击-Jupyterlab

控制台内输出代码
cd /root/Retrieval-based-Voice-Conversion-WebUI && python infer-web.py --port 6006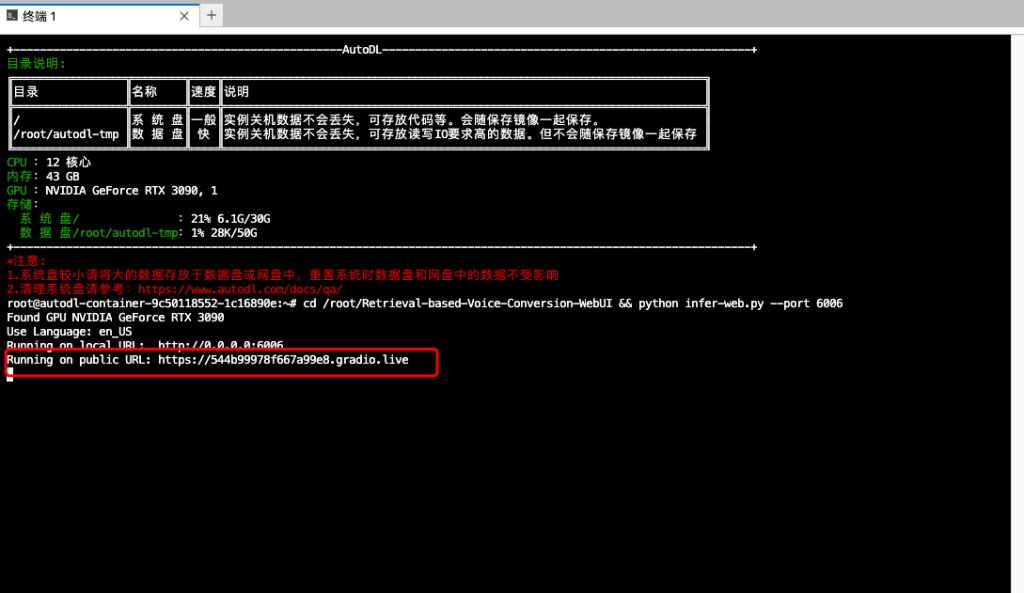
我们访问终端给出的链接进行访问
详细功能说明
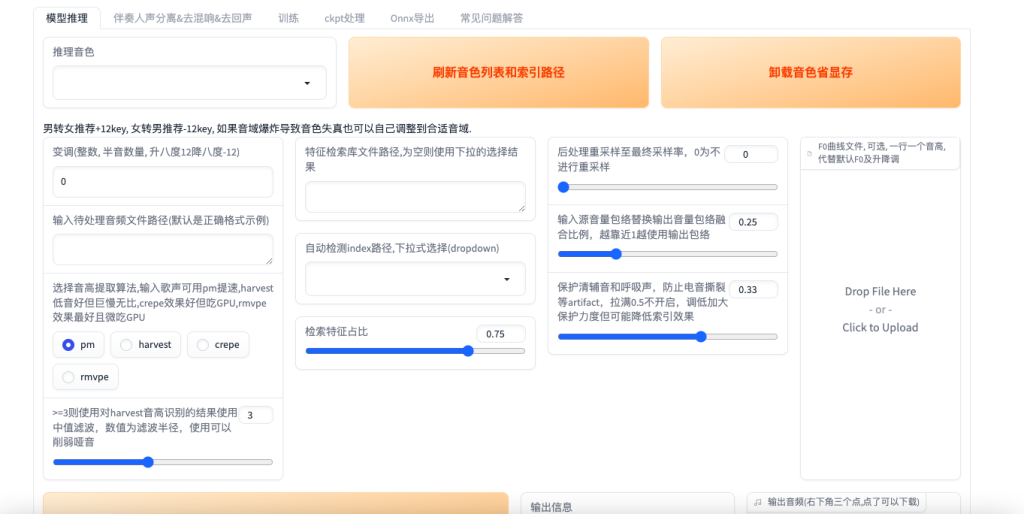
模型推理
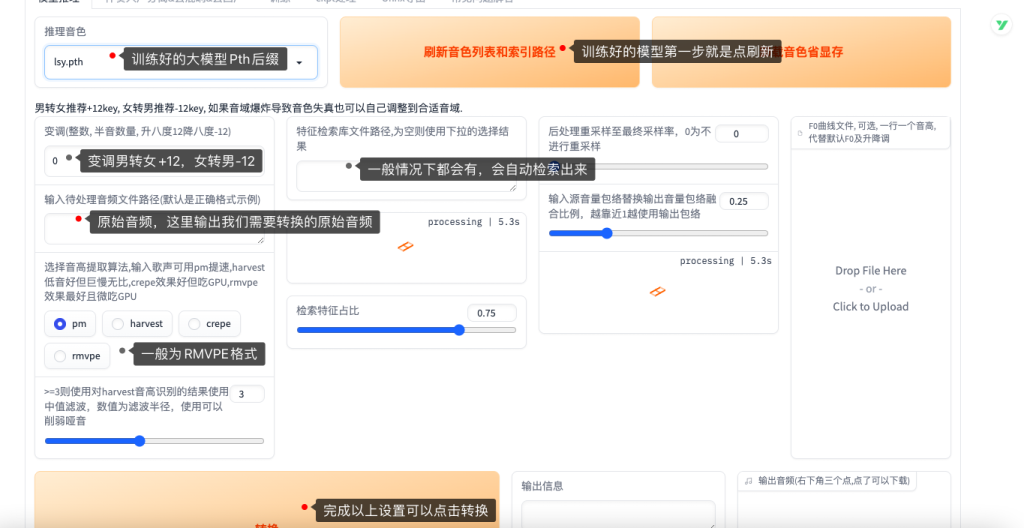
训练好的模型第一步就是得刷新,才能正常的显示在推理音色当中,男转女+12,女转男-12即可,其他的设置可以跟着上图设置,其他默认不动,完成设置点击转换即可。
伴奏人声分离
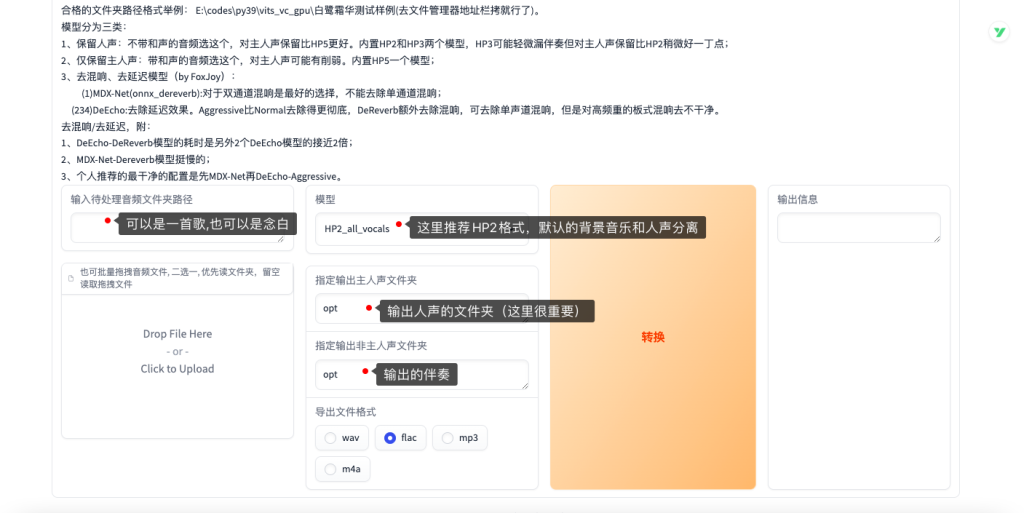
这里可以根据上方提示进行,需要注意的是音频是否带混响,再决定不同的模型。
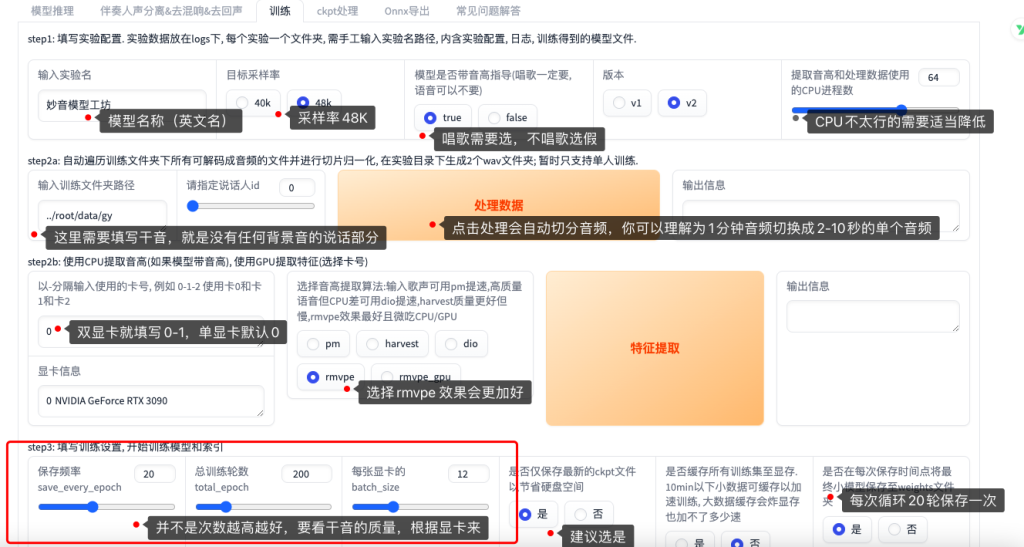

这里需要注意的是,干音一定要没有背景音,杂音,或者其他什么声音,按照以上设置即可,这里说一下轮数不一定是越高越好,我们测试一下来干音质量好的情况下50轮也是能可以的,输入的训练音频最少最少最少不能低于一分钟,会失败。 训练完成后会保存在weights 文件夹内。
模型融合
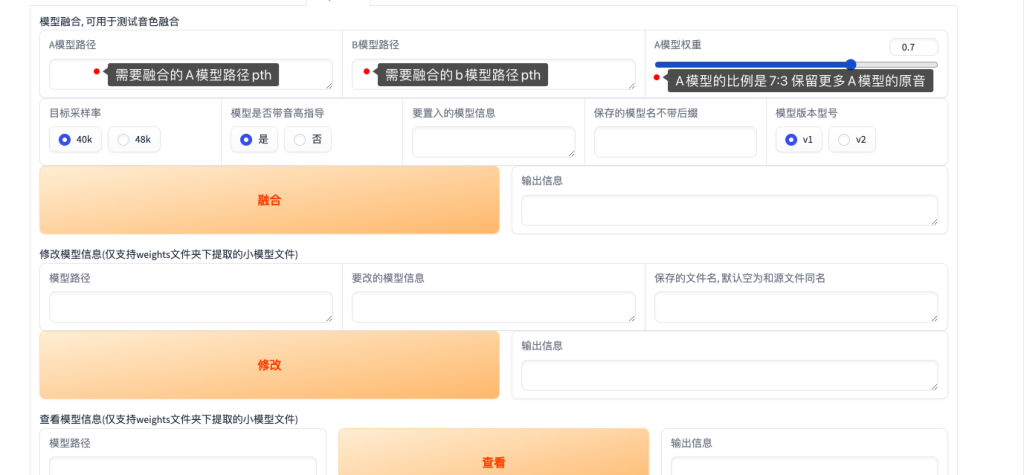
通俗的来说就是将A和B模型进行融合,输出C模型,这里需要注意的一点就是A和B融合的比例,如果你想保留更多A模型的音色你可以拉到超过0.5的比例。
其他说明
其实训练RVC模型步骤就并没有多复杂,复杂的是如何对干音的处理,我们大部分下载过来的干音就算去除背景音还是不太完美,导致后期推理的时候会出现各种奇奇怪怪的问题,训练好的大模型最重要的是干音部分的处理。


















请登录后查看评论内容