![[原创]RVC微调底模-悦 f048K - 妙音-RVC音色模型工坊-妙音-RVC音色模型工坊](https://klrvc.com/wp-content/uploads/2025/04/c6fc7c592720250402175307.jpg)

很高兴,今天我们发布妙音微调后的新基础模型,该模型是在RVC2的基础模型上微调的,下面是训练的部分语言介绍时长。
新增:日语≈10小时高质量语音包括多人说话数据集以及部分动漫数据集。
新增:中文≈15小时高质量录音棚音质。
新增:2小时中文歌曲数据集。
目前在1.0中我们暂时新增了这两种语音,至于新微调的底部训练出的模型质量是否能达到比较好的一个水平,我们正在测试当中,但目前我们已经实现用很少部分的数据能成功训练出一个推理模型。这个一个很不错的开始。
由于微调的模型数据比较大,这对于我们GPU特别紧张的情况下,我们只step了30000步。
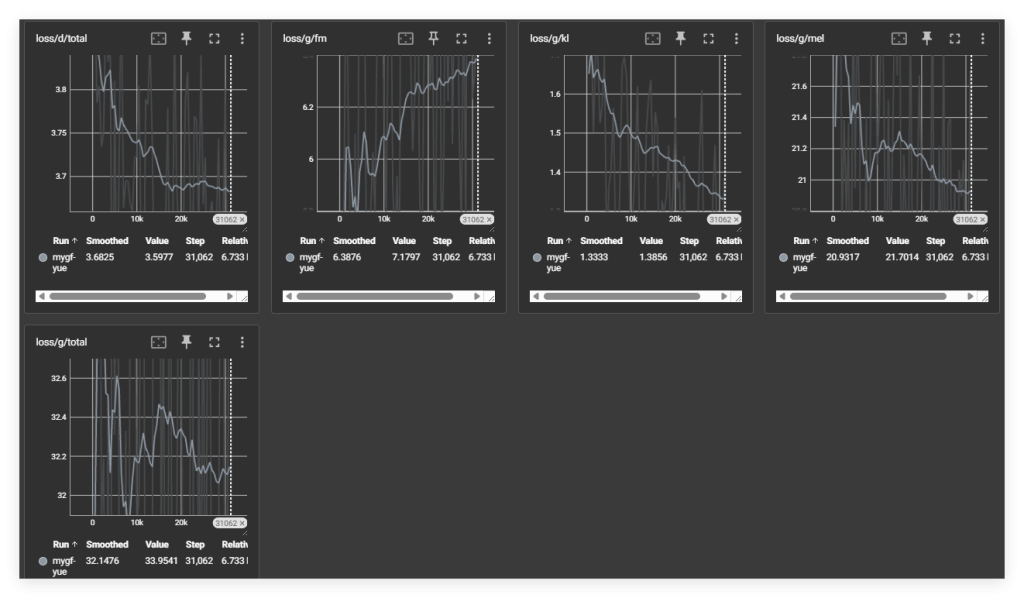
这张曲线如果看不懂的话,可以在使用帮助中查看我们之前写的一篇文章有详细说明,我们的损失值一直都是跌宕起伏至少看G模型的损失值是这样的,我无法通过少量的训练去判断,但目前在测试这几个推理模型下来,表现还是挺好的,毕竟在RVC_v2中,底模就很优秀。
下面我将会用几段音频(底部模型直接推理,原数据集未训练。)
原音频
底部模型推理
在未给底部模型加入原音频数据情况下,底部模型的推理效果也能达到6-7分相似。
接下来第二段
原音频
底部模型推理
如果你仔细听,这些原音频虽然未在底部模型中,但是输出的音色却是非常的相似,在后续的推理模型训练中,只需要使用我们的底模+说话人(可能少部分的说话)+情绪语句,即可得到一个很好的推理模型。
当然后续我们将会继续完善该模型,当然永久炼丹师优先下载享用。
下面是使用教程:
将模型放入原生RVC项目中:
assets\pretrained_v2
直接将D以及G开头的两个pth文件解压到本文件夹目录下,请勿更改使用名称。
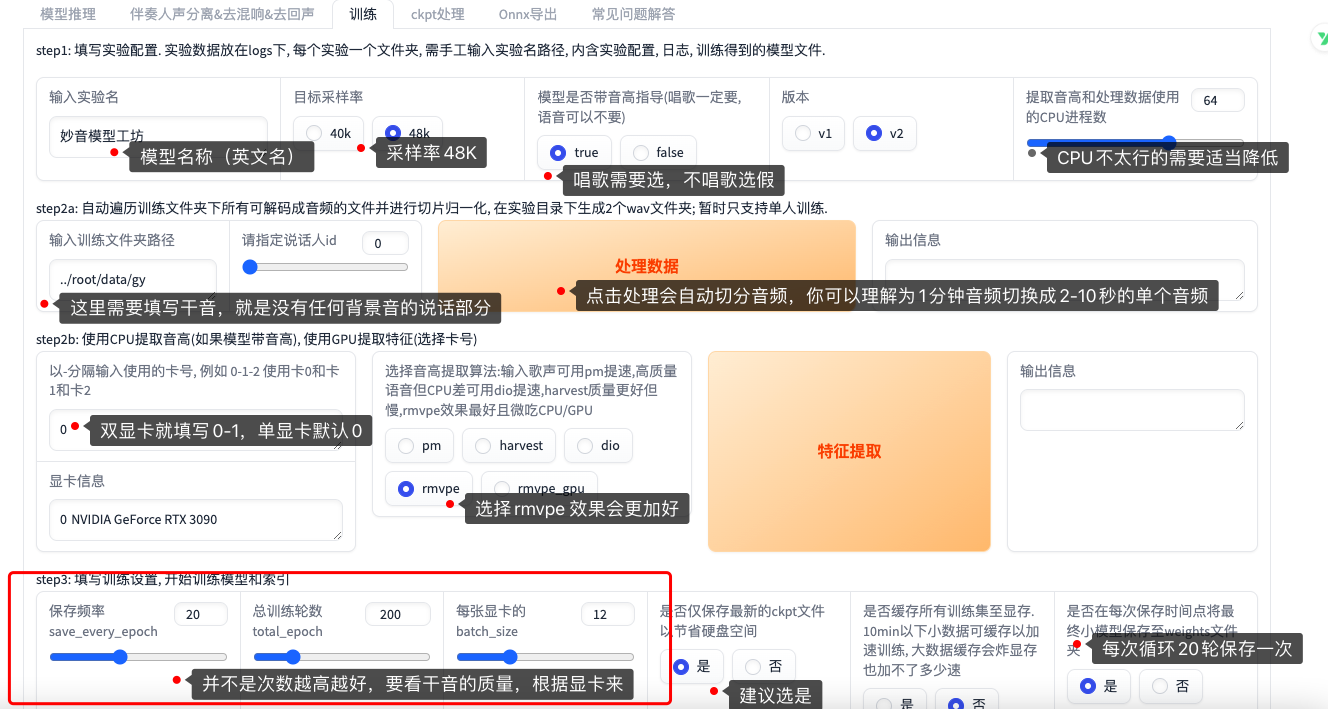
需要注意在训练当中的这几个参数。
![图片[2]-[原创]RVC微调底模-悦 f048K - 妙音-RVC音色模型工坊-妙音-RVC音色模型工坊](https://klrvc.com/wp-content/uploads/2025/04/d66ce7c70920250402173441.png)
目标采样率+高音+版本必须保持一致,因为我们的微调模型是在f048K下微调,所以这里一定要保持一致。
![图片[3]-[原创]RVC微调底模-悦 f048K - 妙音-RVC音色模型工坊-妙音-RVC音色模型工坊](https://klrvc.com/wp-content/uploads/2025/04/cc11d41af320250402173636-300x226.png)
之后修改模型路径如果你目标采样率选择正确后你只需要
G模型路径:
assets/pretrained_v2/G_mygfyue48K.pth
D模型路径:
assets/pretrained_v2/D_mygfyue48K.pth
在训练前请注意训练模型的路径。
由于我们没有与RVC_V2的底模有过进行对比,这个将会在后期空闲时间进行比对。
D_mygfyue48K(model_hash):b3640c5ac8fdc81b3934be1173d4f2a6ec2d815742f477632f9a727a442a7034
G_mygfyue48K(model_hash):087e08d6e3992de28deba1cd87c7a56eac5b257b8b72d97c8fc83c94f2a6e99b
后续计划,继续微调其他语音,对唱歌部分进行微调。
![[原创]RVC微调底模-悦 f048K-妙音-RVC音色模型工坊](https://klrvc.com/wp-content/uploads/2025/04/c6fc7c592720250402175307-300x169.jpg)


















请登录后查看评论内容